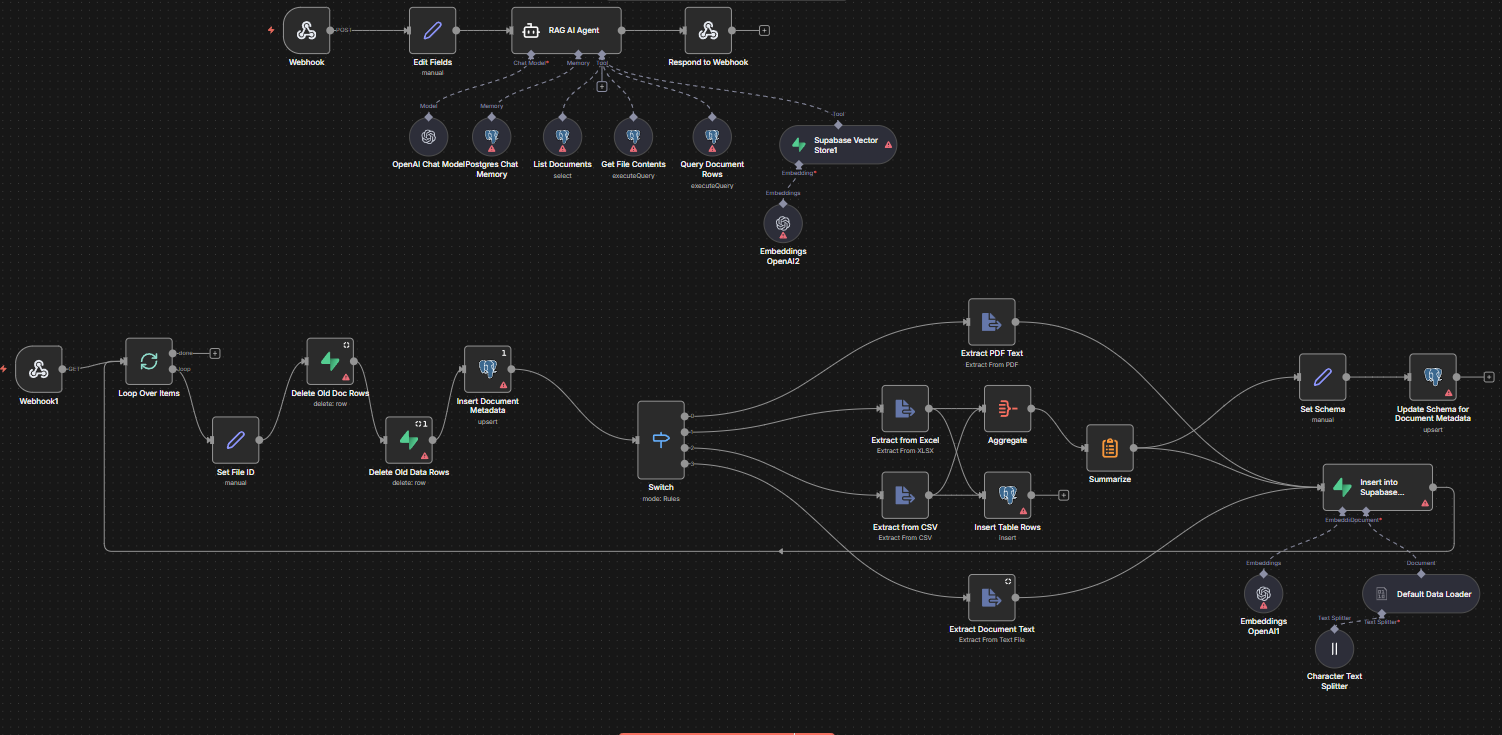

Sistema RAG completamente local que permite analizar documentos confidenciales con IA sin que los datos salgan de la infraestructura de la empresa. Base de datos vectorial opensource, LLM local, y control total sobre compliance y privacidad.
Cada vez que usas ChatGPT, Claude, Gemini o cualquier LLM cerrado para analizar documentos internos, estás enviando tus datos a servidores externos.
Contratos. Informes financieros. Estrategias de producto. Datos de clientes.
Todo sale de tu infraestructura.
Y sí, todos estos servicios tienen políticas de privacidad y compliance. Pero la pregunta real no es si confías en ellos.
La pregunta es: ¿tu departamento legal, tus auditores y tus clientes aceptan que datos confidenciales sean procesados en servidores de terceros?
Para muchas empresas, especialmente en sectores regulados (legal, financiero, salud, gobierno), la respuesta es un rotundo no.
Construimos un sistema RAG (Retrieval Augmented Generation) que mantiene todos tus datos dentro de tu infraestructura.
Utilizamos Supabase (opensource) para almacenar embeddings y documentos. La base de datos vive en tu servidor, no en la nube pública.
Modelos como Llama 3, Mistral o Phi-3 ejecutándose completamente en tu propio servidor. Sin llamadas a APIs externas. Sin dependencia de servicios de terceros.
Sistema de gestión que permite a los equipos subir y organizar archivos sin tocar código. Procesamiento automático de PDFs, Word, Excel, imágenes y más.
Interfaz natural para interactuar con los documentos. Los usuarios hacen preguntas en lenguaje natural y obtienen respuestas contextuales basadas en el contenido real de sus documentos.
Tus datos nunca salen de tu infraestructura.
Los LLMs open source no son tan potentes como GPT-4 o Claude Opus. Todavía.
Pero para la mayoría de casos de uso empresariales (análisis de documentos, extracción de información, Q&A sobre conocimiento interno), son más que suficientes.
Y lo más importante: te dan control total.
Análisis de contratos, búsqueda de cláusulas específicas, comparación de términos entre documentos, extracción de obligaciones y fechas críticas.
Análisis de informes financieros confidenciales, extracción de KPIs, comparación de rendimiento histórico, generación de resúmenes ejecutivos.
Análisis de CVs, búsqueda de candidatos según criterios específicos, generación de informes de evaluación, análisis de políticas internas.
Análisis de documentación técnica, búsqueda en bases de conocimiento internas, comparación de especificaciones, extracción de insights de investigación.
La adopción de IA en empresas no tiene que significar perder control sobre tus datos.
Solo necesitas construir la arquitectura correcta desde el inicio.
Control sobre tus datos. Control sobre tu infraestructura. Control sobre tu cumplimiento normativo.


